The AI-Native Split
Six frontier models now score within 1.3 points of each other. OpenAI shipped a million lines of code with three engineers. The constraint has moved from the model to the harness.

Six frontier models now score within 1.3 percentage points of each other on SWE-bench Verified. OpenAI just shipped a million lines of production code with zero humans writing any of it. And most of the industry is still debating whether to trust AI to write a function. The gap between those three sentences is the only enterprise AI story that matters right now.
In February 2026, OpenAI published an engineering post describing a five-month experiment that should have reframed the AI debate but didn’t. A team of three to seven engineers built and shipped an internal beta product containing roughly one million lines of production code across application logic, infrastructure, tooling, and documentation. Zero lines were written by a human. About 1,500 PRs were generated and merged by Codex agents. The team estimates the work took one-tenth the time a human team would have required. 1
The interesting number in that post isn’t a million. It’s three. Three engineers, 3.5 merged PRs per person per day, on a codebase they had no hand in writing. They weren’t reviewing diffs. They were designing the environment that made the diffs correct.
In a March 2026 disclosure, Anthropic reported that Claude Opus 4.6 had spent twenty minutes with a copy of Firefox and identified a Use-After-Free vulnerability in the JavaScript engine — the kind of memory-safety bug that lets attackers overwrite data with arbitrary payloads. An Anthropic researcher validated it first, then two additional researchers confirmed it, and they submitted the report to Mozilla through Bugzilla along with a Claude-written candidate patch. By the time the first vulnerability was through triage, the same model had found fifty more unique crashing inputs. Over a two-week window, the effort produced 22 vulnerabilities — 14 classified by Mozilla as high-severity — across 112 distinct reports.2 That is root-cause analysis at staff-plus level, on one of the most security-reviewed codebases in the industry, at a rate no human team can match.
Nine months earlier, Stack Overflow’s 2025 Developer Survey — 49,000 respondents across 177 countries — reported that 46% of developers actively distrust the accuracy of AI output, up from 31% in 2024.3 That is a 15-point acceleration in distrust over twelve months, at the same time AI-tool adoption climbed to 84%.4
All three of these facts are real. The resolution isn’t that one of them is wrong. It’s that they measure different populations doing different kinds of work with different infrastructure, and most discussions of enterprise AI in 2026 are conflating them. The unit of analysis that separates them is what OpenAI’s team called the harness — and which side of it your organization sits on is the only question that’s going to matter in twelve months.
The Matrix That Organizes Everything
Figure 1. AI Adoption (X-axis) × Harness Maturity (Y-axis). The Stack Overflow respondents cluster in the bottom-right. OpenAI, Anthropic, and Google core sit in the top-right. The industry’s center of gravity is drifting right along the adoption axis without climbing the harness axis.
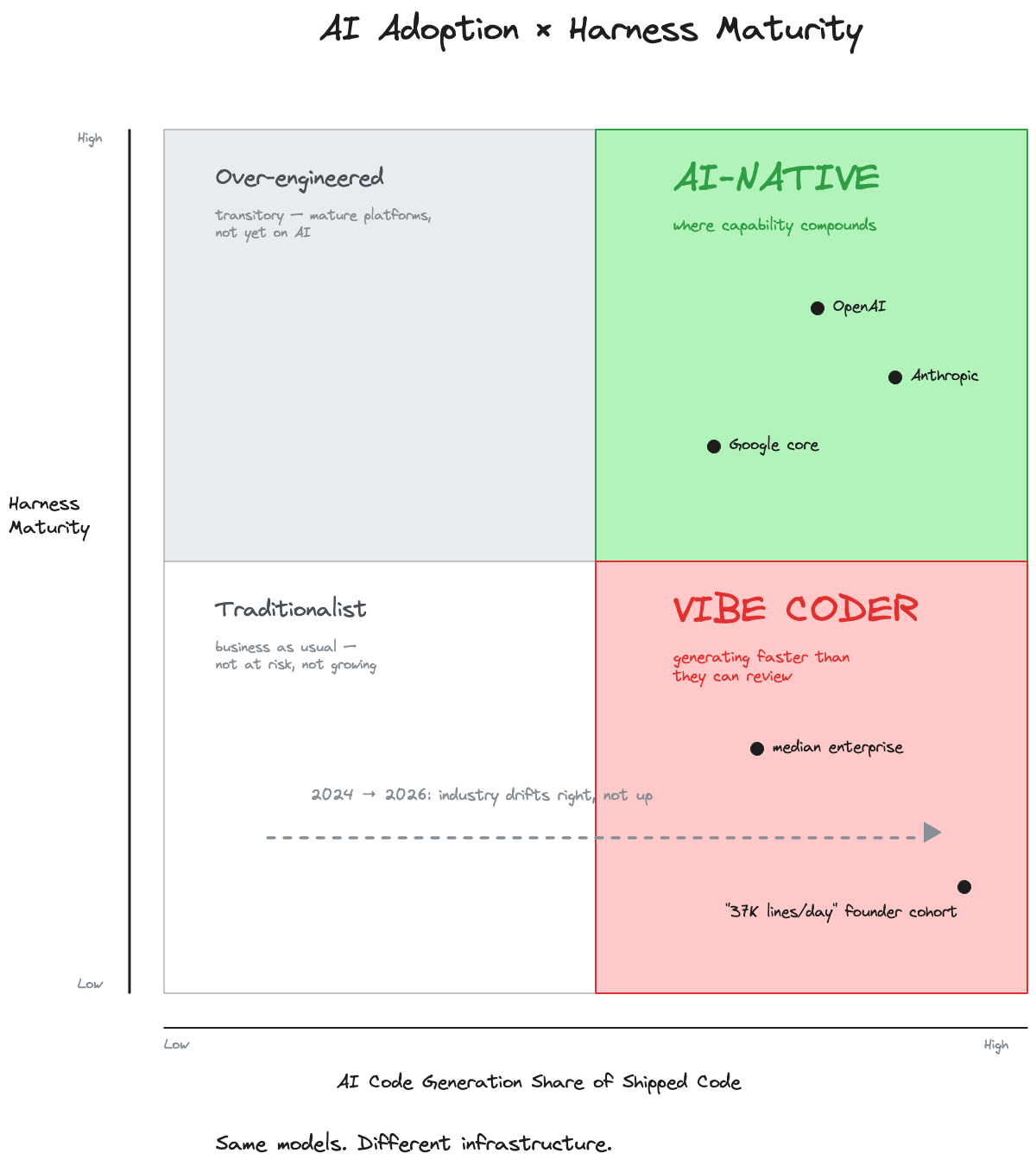
What the chart shows that prose can’t: the Stack Overflow survey — which recruits respondents through its own site, a channel disproportionately frequented by individual contributors on traditional codebases, not platform engineers at AI-native shops — is measuring the bottom-right quadrant. The OpenAI post is measuring the top-right. Same year, same underlying models. The axis that separates them isn’t trust or skill. It’s infrastructure.
The Capability Floor Just Moved
The most important development in the last six months isn’t a single benchmark result. It’s that six different frontier models — Claude Opus 4.5, Claude Opus 4.6, Gemini 3.1 Pro, MiniMax M2.5, GPT-5.2, and Claude Sonnet 4.6 — now score within 1.3 percentage points of each other on SWE-bench Verified, all clustered between 79.6% and 80.9%.5 MiniMax M2.5 achieves 80.2% on open weights at $0.15 per million input tokens and $1.20 per million output tokens.6 The premium tier and the budget tier have collapsed into a band.
Two things follow from that convergence.
First, the question “which model should we use?” is now a rounding error relative to “what infrastructure are we running around the model?” When the top six models on the public leaderboard sit within 1.3 points of each other, the harness — not the model — drives the remaining variance.
Second, capability is still accelerating. METR’s time-horizon study measures the length of tasks a model can complete with 50% reliability. Task horizons doubled approximately every seven months from 2019 through early 2025.7 In the 2024–2025 window specifically, the doubling time compressed to roughly four months.8
Figure 2. Every blue dot is a measured model from METR’s public v1.1 benchmark dataset. The July 2025 METR productivity study (the one that found experienced developers were 19% slower with AI) measured Claude 3.5 / 3.7 Sonnet at ~60 minutes of task horizon. Today’s frontier, Claude Opus 4.6, sits at ~12 hours — about 12× further along, in eleven months.
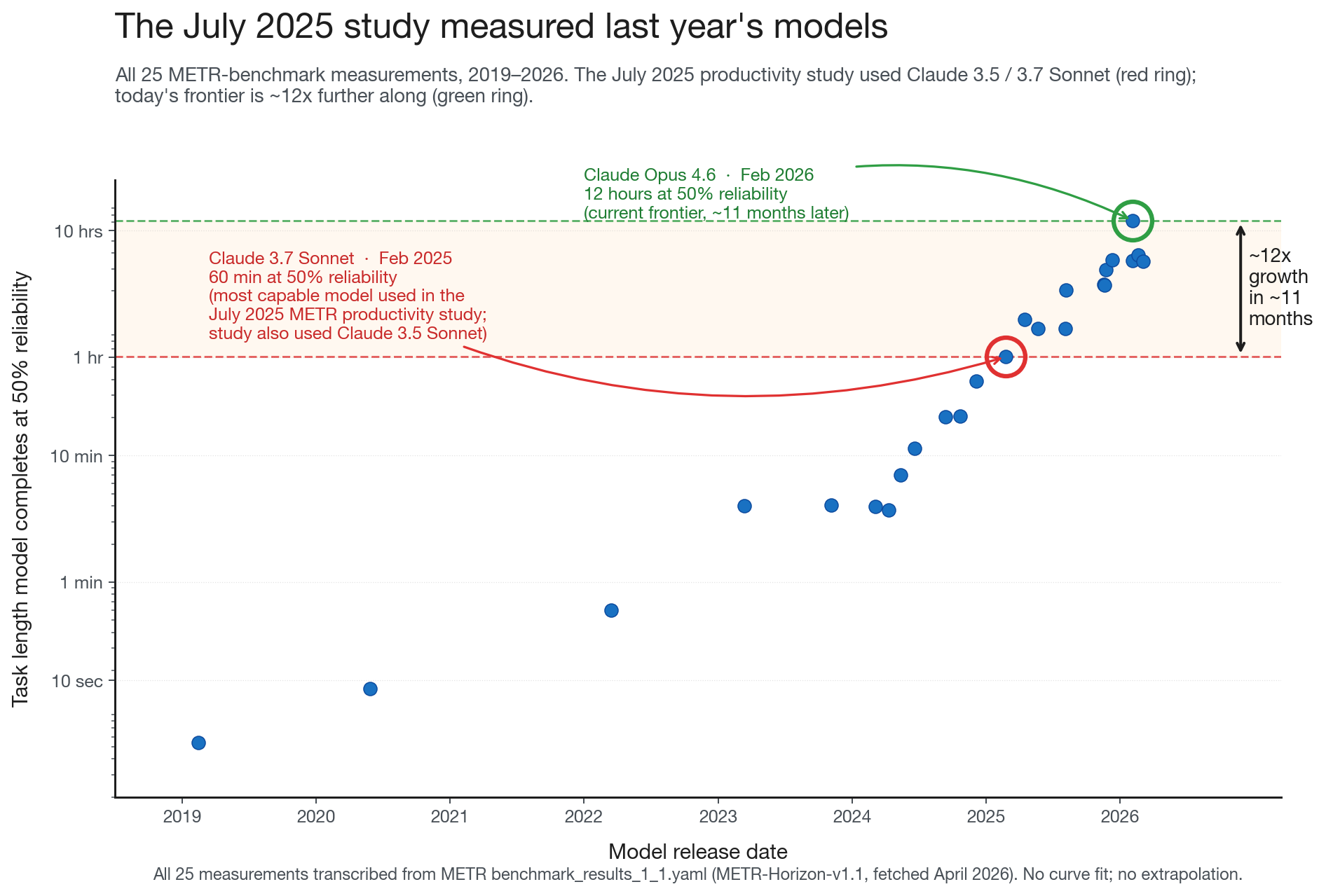
The July 2025 METR productivity study that everyone cites measured Claude 3.5 / 3.7 Sonnet — the frontier models at that time.9 Since then, by METR’s own capability metric, we have moved through three to four doublings. Citing the productivity finding as current-state evidence is like citing a 2005 smartphone survey to argue that phones aren’t good at navigation.
The 2024 DORA report sits in the same category. It surveyed 39,000 professionals and found that increased AI adoption correlated with a 7.2% drop in delivery stability.10 The result is real. It measured tools and models from 2023–2024. Faros AI’s 2025 telemetry study, running alongside the DORA work, showed individual throughput up sharply — 21% more tasks, 98% more PRs merged — while DORA’s organizational-stability metrics stayed under pressure.11 These are important findings about what happens when AI adoption outruns harness infrastructure. They are not findings about what AI can or cannot do in 2026.
The production validation is where the shift becomes concrete. Sentry’s Seer, built on Claude, now processes over a million root-cause analyses a year and delivers near-immediate reviews on more than 600,000 pull requests a month — a deployed production system operating at scale, not a benchmark result.12 The Mozilla partnership produced real Firefox vulnerabilities in twenty minutes, with CVE submissions, not as a demo. Together with the SWE-bench convergence and the METR trajectory, these say the same thing: on the work senior engineers historically dominated — root-cause analysis, debugging, investigating complex failures — the capability floor is no longer the constraint.
Which means the constraint has moved. It is now the harness that decides whether your organization harvests that capability or watches it slip through gaps in your review and deployment infrastructure.
The Harness: What AI-Native Engineering Actually Looks Like
A harness, in OpenAI's usage, is the set of systems that catch model errors mechanically rather than asking a human to catch them cognitively. Across every AI-native team that has publicly documented its stack, five components show up consistently.
Figure 3. Human intent flows into coding agents, which iterate against mechanical gates (type checks, lints, tests, evals, security scans), get reviewed by agent reviewers, emit production telemetry back to the agents, and deploy through canary rollout. Human review is optional at every stage. Cognitive review is removed from the critical path.
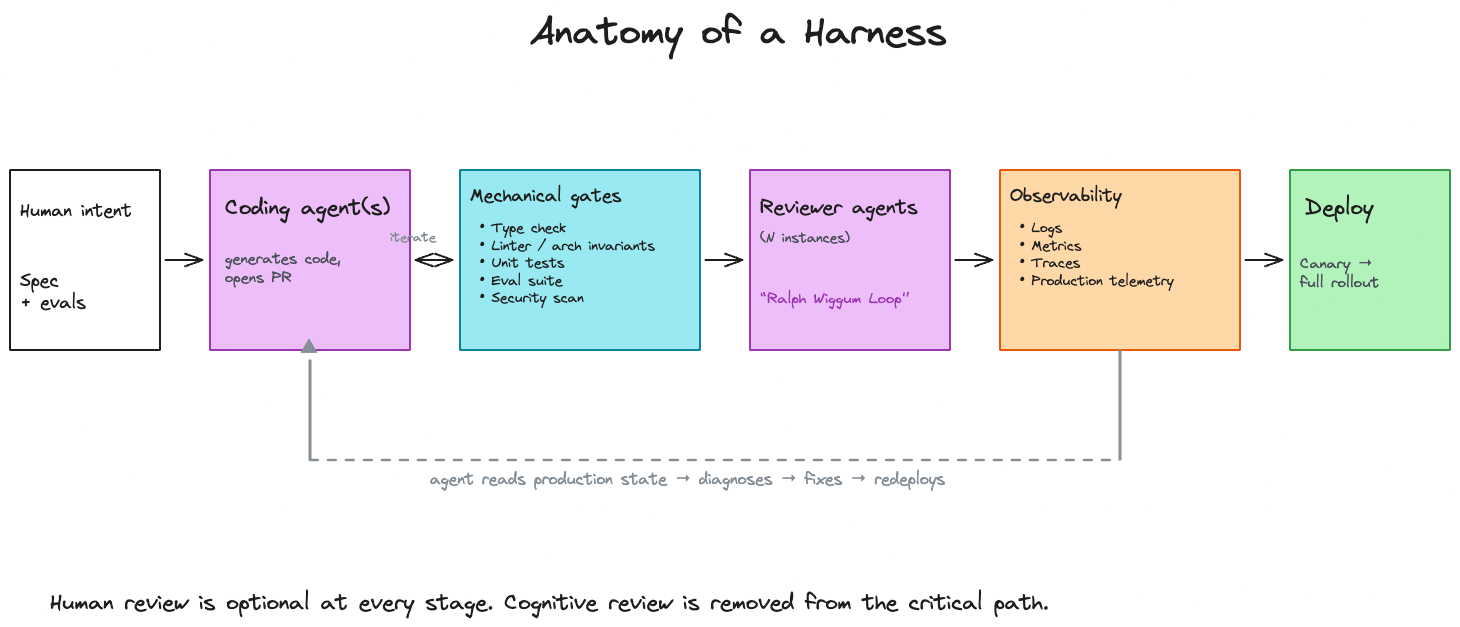
Agent-legible architecture. Code and repository structure optimized for model comprehension. Strong typing, consistent patterns, dense inline documentation the model can use as context. OpenAI’s team enforces architectural invariants with custom linters and structural tests — rules that are cheap to encode once and run every PR. The point isn’t that AI is careless. It’s that mechanical invariant enforcement is cheaper than probabilistic hope.
Eval-first development. Before features are written, tests and evaluation harnesses define what “correct” means for this change. The agent writes code to pass the evals. Braintrust, Promptfoo, DeepEval, Weights & Biases Weave — the eval-as-CI tooling market barely existed eighteen months ago and is now standard infrastructure at every AI-native team.13 Teams that have been writing LLM evals for 18+ months are in a structurally different position than teams writing their first one now.
Agent-to-agent review. OpenAI’s team calls it the “Ralph Wiggum Loop” — one agent opens a PR, other agents review it, propose fixes, and iterate until reviewers are satisfied. Human review becomes optional. This is the specific mechanism that kills the cognitive-review bottleneck the 2025 productivity studies measured. When agents are reviewing agents, the 19% slowdown doesn’t apply — there’s no human in the critical path to be slowed down.
Observability the agent can read. Logs, metrics, and traces exposed to the coding agent through MCP or similar interfaces, so the agent can diagnose its own failures, reproduce the bug, fix it, and verify the deployment — without human escalation. This is the component most enterprise teams are furthest behind on, and the one that lets you capture the Sentry-style RCA throughput in your own systems rather than only in vendor case studies.
Deterministic gates. Type checks, security scans, integration tests, canary deploys —the same DevOps infrastructure mature teams have always had, with acceptance thresholds calibrated for AI-generated volume rather than human volume. Change failure rate as the gate, not lines of code as the metric.
The published outputs of this stack are the evidence. Anthropic CEO Dario Amodei said at Dreamforce in October 2025 that AI now writes roughly 90% of the code at Anthropic.14 Google’s Sundar Pichai told investors in 2025 earnings calls that more than 30% of new code at Alphabet was AI-generated, up from 25% six months prior.15 Fortune’s January 2026 reporting on engineers at Anthropic and OpenAI whose code is now 100% AI-generated is not aspirational.16 It is the logical endpoint of a harness that works at a moment when the underlying model is good enough to ship.
Why the Enterprise Capex Is Rational
Oracle's $156 billion AI infrastructure commitment — tied to a five-year, $300 billion cloud deal with OpenAI — funded by cutting up to 30,000 employees.17 Atlassian cutting 1,600 jobs, over 900 of them in R&D, to self-fund AI and enterprise-sales investment.18 Home Depot hiring Ford’s Chief Data, AI, and Analytics Officer, Franziska Bell, as its new EVP and CTO.19 S&P Global creating a net-new Chief Technology and Transformation Officer role, filling it with Firdaus Bhathena.20
Under the trust-collapse frame, none of this makes sense. Under the capability-plus-harness frame, all of it does.
The capex is not a bet that foundation models will improve. The models are already good enough. The capex is a bet that the enterprise customer base is migrating from the bottom-right quadrant to the top-right, and whoever owns the infrastructure layer under that migration captures the economics. Oracle is betting that by the time the Fortune 500 has built harnesses, the GPU hours and cloud primitives to run them will run on Oracle. The risk isn’t that AI disappoints. The risk is that Oracle’s stack isn’t compelling enough versus AWS, Azure, and GCP to capture the demand it has already priced in.
The CTO hires tell you where boards believe their engineering organizations sit on the 2x2. When Home Depot hires externally rather than promoting, the signal is: we are not in the top-right, and incremental change won’t get us there. S&P Global creating a net-new C-level role is the same signal at higher intensity. Atlassian’s internal version — cutting the R&D organization that built the old stack and splitting the CTO role into two AI-native mandates (CTO Teamwork and CTO Enterprise and Chief Trust Officer) — is the top-right move from a company that already has some of the harness in place.
None of this is panic. It is the most rational response available to boards that understand the bifurcation and the trajectory. “AI transformation” in every one of these announcements is code for: we are moving from the lower half of the 2x2 to the upper-right, and we’re buying or promoting the leadership that can get us there before the capability gap compounds.
Building the Harness
The question worth asking in mid-2026 is not whether to adopt AI faster. Adoption is already happening. The question is whether the infrastructure being built around that adoption moves your organization up the harness axis, or just further right on the adoption axis without a floor under it. Five principles that hold up under the current capability picture:
Build evals before you build features. A feature without an eval is a feature no agent can safely maintain. The eval suite is not QA infrastructure in the old sense — it is the specification the agent iterates against. Start writing evals now, even if they feel redundant. The compounding starts immediately.
Design for agent-to-agent review. Most code-review infrastructure was designed for human reviewers at human volume. Retrofitting it to agent scale is not the same as designing for agent scale. Make human review optional at every stage. Put agent reviewers in the loop by default.
Make observability agent-readable. Exposing logs, metrics, and traces through MCP or similar agent-accessible interfaces closes the feedback loop — the agent reads production state, diagnoses its own failures, and fixes them without human escalation. This is the single highest-leverage component of the harness, and the one most organizations are furthest behind on.
Measure change failure rate, not lines of code. Lines-of-code-per-day is a metric that only looks like productivity if you don’t also measure reliability. Garry Tan’s public “37,000 lines of code per day” claim became the cautionary tale here — the number became a story about lines generated, not lines shipped reliably.21 DORA’s four metrics — change failure rate, time-to-restore, deployment frequency, lead time — distinguish real productivity from accumulating debt. Instrument them before you scale AI adoption, not after.
Hire harness designers, not diff reviewers. The engineers who will matter in 2027 are the ones who can architect the environment that makes agent output correct by construction. This is a new role. The market has not yet priced it. That is the hiring arbitrage for the next twelve months.
The Window Is Shorter Than It Looks
If METR's trajectory holds — doubling every four to seven months, accelerating rather than plateauing — then models available in mid-2027 will have two to four times the time-horizon capability of the ones we're benchmarking today. That is the acceleration the Mozilla and Sentry results are early signals of: models that find real vulnerabilities in production codebases in twenty minutes, not models that hopefully autocomplete a function in an IDE.
The AI-Native quadrant has a network effect most CTOs have not yet internalized. Each harness component makes the next one cheaper to build. Agent-legible architecture makes eval generation cheaper. A mature eval suite makes agent-to-agent review more reliable. Agent-readable observability makes the whole loop self-healing. A team eighteen months into the transition can deploy new agent capabilities in days against increasingly capable models. A team starting from the Vibe Coder quadrant now will spend six months getting to the same position, against models that will be meaningfully better by the time they arrive.
The Vibe Coder quadrant is a transient state. Either the harness gets built and the team climbs into the top-right, or the capability gap widens fast enough that catching up stops being possible on a reasonable time horizon. The organizations still debating whether the models can be trusted are debating the wrong question. The models are not the constraint. The infrastructure around them is. And the infrastructure takes time to build — time that is compounding against the organizations that have not started.
Two years from now, the gap between the top-right and bottom-right quadrants will not be measured in trust scores or survey sentiment. It will be measured in which products shipped, which codebases stayed reliable under velocity, and which engineering organizations still exist in a recognizable form. The 46% Stack Overflow distrust figure, read in 2028, will look like what it is: a lagging indicator from the cohort that didn’t build the harness in time on models that were already capable enough to require one.
The organizations reading that figure as “AI isn’t ready” are going to lose to the ones reading the OpenAI post as a blueprint.
About the Author
Daniel Voigt is the founder and principal engineer of TeqEngine, an AI-native software consultancy that builds AI systems and infrastructure for Fortune 500 enterprises and venture-backed engineering teams.
Daniel has been the lead engineer and architect who built the system and infrastructure powering an app that hit #1 on the App Store and handles 100M+ messages a day, served as CTO and built the technology behind an a16z-backed acquisition, and shipped the core products at multiple AI-native startups with significant raises and MAUs.
Enterprise AI Patterns is a weekly essay on what it actually takes to ship AI in production — for leaders and builders designing systems that hold up under agent-scale volume. This is the first issue.
Ryan Lopopolo et al. “Harness engineering: leveraging Codex in an agent-first world.” OpenAI Engineering, February 2026. https://openai.com/index/harness-engineering/
Anthropic. “Partnering with Mozilla to improve Firefox’s security.” March 6, 2026. https://www.anthropic.com/news/mozilla-firefox-security
Stack Overflow. “Stack Overflow’s 2025 Developer Survey Reveals Trust in AI at an All Time Low.” Press release, July 29, 2025. https://stackoverflow.co/company/press/archive/stack-overflow-2025-developer-survey/
Stack Overflow. “2025 Developer Survey — AI section.” https://survey.stackoverflow.co/2025/ai
SWE-bench Verified public leaderboard, March 2026 snapshot. Top six: Claude Opus 4.5 (80.9%), Claude Opus 4.6 (80.8%), Gemini 3.1 Pro (80.6%), MiniMax M2.5 (80.2%), GPT-5.2 (80.0%), Claude Sonnet 4.6 (79.6%).
https://www.swebench.com/
MiniMax. “MiniMax M2.5: Built for Real-World Productivity.” 2026. https://www.minimax.io/news/minimax-m25
METR. “Measuring AI Ability to Complete Long Tasks.” March 19, 2025. https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
AI Digest. “A new Moore’s Law for AI agents.” Analysis of METR trajectory data through 2026. https://theaidigest.org/time-horizons
METR. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” July 10, 2025. https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
Google Cloud / DORA. “Announcing the 2024 DORA report.” October 22, 2024. https://cloud.google.com/blog/products/devops-sre/announcing-the-2024-dora-report
Faros AI. “DORA Report 2025 Key Takeaways: AI Impact on Dev Metrics.” September 25, 2025. https://www.faros.ai/blog/key-takeaways-from-the-dora-report-2025
Anthropic / Sentry. “Sentry helps developers accelerate debugging and ship fixes faster with Claude.” Case study. https://claude.com/customers/sentry
Braintrust. “Best AI evals tools for CI/CD in 2025.” October 2025. https://www.braintrust.dev/articles/best-ai-evals-tools-cicd-2025
Dario Amodei, remarks at Dreamforce (conversation with Marc Benioff), October 2025. Coverage: StartupNews.fyi, “90% of code at Anthropic now written by AI.” October 17, 2025. https://startupnews.fyi/2025/10/17/90-of-code-at-anthropic-now-written-by-ai-ceo-dario-amodei-says-humans-still-essential/
Sundar Pichai, Alphabet investor calls, 2025. Coverage: multiple outlets; Pichai said on Q3 2024 call that 25% of new code at Alphabet was AI-generated, subsequently updating the figure to more than 30% in 2025.
Jessica Mathews. “Top engineers at Anthropic, OpenAI say AI now writes 100% of their code.” Fortune, January 29, 2026. https://fortune.com/2026/01/29/100-percent-of-code-at-anthropic-and-openai-is-now-ai-written-boris-cherny-roon/
Oracle Corporation capex commitment estimated at $156 billion (TD Cowen), tied to the five-year, $300 billion cloud-compute deal with OpenAI announced September 2025. See Bloomberg, “Oracle to Cut Up to 30,000 Jobs to Fund AI Buildout,” March 2026; and Siôn Geschwindt, “Oracle is cutting up to 30,000 employees to pay for AI data centres.” The Next Web, March 31, 2026. https://thenextweb.com/news/oracle-layoffs-march-2026
Mike Cannon-Brookes (co-founder/CEO, Atlassian), layoff announcement, March 11, 2026. Bloomberg, “Atlassian (TEAM) CEO Announces Layoffs of 1,600, Citing AI Shift.” https://www.bloomberg.com/news/articles/2026-03-11/atlassian-team-ceo-announces-layoffs-of-1-600-citing-ai-shift. Of the 1,600 roles cut, more than 900 were in R&D. CTO role was split into CTO Teamwork (Taroon Mandhana) and CTO Enterprise & Chief Trust Officer (Vikram Rao).
The Home Depot. “The Home Depot Names Franziska Bell EVP and Chief Technology Officer.” PR Newswire, March 31, 2026.
S&P Global. “S&P Global Names Firdaus Bhathena as Chief Technology & Transformation Officer.” Press release, March 31, 2026.
Public “37,000 lines of code per day” claim, April 2026; subsequently audited by developers who found significantly degraded code-review quality. Fast Company, “Y Combinator’s CEO says he ships 37,000 lines of AI code per day. A developer looked under the hood.” https://www.fastcompany.com/91520702/y-combinator-garry-tan-agentic-ai-social-media